
I have some good news to share. After almost two years under the cloud of litigation regarding a challenge to one of our patent applications, we have reached a settlement that concludes the issue. The Patent Trials and Appeals Board (PTAB) ruled in our favor by denying the patent derivation claim made against us. This was on top of earlier rulings in our favor. What is more, both our patent applications have now been allowed.
While the terms of the settlement remain confidential, this has been a costly exercise for us. For me personally, this was very difficult. Not only did I have to defend my honor and integrity, but I have had to spend half of my personal life savings in the defense of Xcential – with no guarantees that I will ever be able to recoup that expense. Using my own savings for a lot of the legal bills was the only way to ensure that Xcential would be able to go on. This has certainly affected my life.
If there is something good to come out of this exercise, it is validation that we’re onto something very valuable. With the litigation behind us and both patents in our pocket, we are now able to proceed forward with our plans to serve our markets – selectively, of course,
Over a decade ago, I wrote a blog questioning why federal bills are written the way they are. For someone experienced with state legislation, federal legislation is quite cryptic and difficult to understand. It turns out that the style of amending law found in federal legislation is the common form and can be found around the world. In the U.S. Congress, this style is known as cut and bite1 amending. With this style, individual word changes are spelled out in a narrative form. For example, here is a section from California Assembly Bill 2748 from the current session:
SECTION 1. Section 21377.5 of the Water Code is amended to read:
21377.5. (a) Notwithstanding Section 21377 of this code or Section 54954 of the Government Code or any other provision of law, the Board of Directors of the Tri-Dam Project, which is composed of the directors of the Oakdale Irrigation District and the South San Joaquin Irrigation District, may hold no more than four regular meetings annually at the a Tri-Dam Project offices. The Board of Directors of the Tri-Dam Project shall adopt a resolution that determines the location of the Tri-Dam Project offices. office that is located in Sonora, California, or Strawberry, California, or within 30 miles of either city.
(b) The notice and conduct of these meetings shall comply with the provisions of the Ralph M. Brown Act (Chapter 9 (commencing with Section 54950) of Part 1 of Division 2 of Title 5 of the Government Code).
You can clearly see what changes are being made. However, if written using cut and bite amending, this equivalent section would read something like:
SECTION 1. Section 21377.5 of the Water Code is amended by:
(a) Deleting the sixth “the” and replacing it with “a”.
(b) After “Tri-Dam Project”, deleting to the end of the subsection and replacing with “office that is located in Sonora, California, or Strawberry, California, or within 30 miles of either city.”
This very terse form of amendment gives no context for the change being made. The change in subsection (a) is completely meaningless without any context. What this all means is that a politician tasked with approving these changes must do a significant amount of work to understand what the changes are all about and why they are being made.
Back in 2013, I questioned why the form found most of the U.S. states including my state of California wasn’t used. As seen in the example above, the U.S. states use a different approach to amending – known as amending in full. In this style of amending, the entire section containing the change is restated and the change is shown (some of the time) as stricken and inserted text, as you would find with track changes in a word processor. This approach has the benefit of making the change much clearer by providing the complete context of the change. In California, this approach is mandated by the State Constitution as amended by Proposition 1-a of 1966. This proposition was overwhelmingly approved by the voters of California. The Speaker of the California Assembly at the time, Jesse Unruh, had pushed through this constitutional amendment to establish professional legislature less beholden to special interests that other pressures that were undermining the effectiveness of the legislature at the time. His reforms were quite sweeping. Among the many changes, one part of this initiative was to make legislation more transparent.
The specific provision that was added, Section 9 of Article IV of the California Constitution, reads:
“A statute shall embrace but one subject, which shall be expressed in its title. If a statute embraces a subject not expressed in its title, only the part not expressed is void. A statute may not be amended by reference to its title. A section of a statute may not be amended unless the section is re-enacted as amended.”
This section of the California Constitution contains two rules. The first is the single subject rule, which limits the scope of each statute. The second is the re-enactment rule, which mandates the amendment in full approach, requiring that each section amended by re-enacting the whole section (essentially a repeal of the prior section and enactment of a new amended section as a single action). Most U.S. states have these same rules or very similar rules. These two rules go together. One of the worries of the re-enactment rule is that, by opening an entire section for re-enactment, unwelcome amendments might be added as part of the political process of winning votes. The single-subject rule is a guard against that behavior.
At the time of my original blog, I learned that adopting these rules in Congress would be impossible. For one thing, the U.S. Code is less regular than state codes or revised statutes, especially in the non-positive titles, and that re-enacting an entire section would be quite complex and could cause other difficulties. Re-enactment rules require consistently bite-sized sections. In addition, the House’s equivalent of the single subject rule, the germaneness rule adopted in 1789, didn’t have quite the same effectiveness as the single subject rule of California. Apparently, the Senate’s equivalent rules, found in the Senate Standing Rule XVI and Rule XXII had even more limited applicability.
As a result, I proposed in my blog that amendments in context be used. With amendments in context, a proposed bill is drafted using the amendments in full style that U.S. states use, from which a cut and bite style bill is generated using automation. With this approach, you get the best of both worlds. The bill is drafted in a form that is easy to understand and easy to manage while the worries of unleashing this amending style are circumvented by retaining the existing amending style for parliamentary procedures. However, at the time, the technology just wasn’t available. Under contract to the Law Revision Counsel, Xcential was just beginning down the path of converting the U.S. Code to processable XML that could feed the automation tools. While we had tools to offer that could do amendments in context, we were constrained by our agreement with California as to how much of our technology could be reused – they had been worried we could inadvertently undermine the successes of Proposition 1-a by empowering the special interests with our technology.
Today, more than a decade later, much has changed. The U.S. Code is available in an XML format we designed and a new more modern LegisPro is available that is both web-based and much more powerful than what we had back then. But there have been other changes too. The Posey Rule has been adopted requiring that a comparative print be provided alongside all proposed law showing how the law will be affected. This comparative print is also generated by Xcential technology and alleviates much of the problem by allowing politicians to understand more easily what it is they are voting on. However, it leaves the complexity of drafting and managing the process of creating and managing the cut-and-bite amendments still to be addressed.
This problem isn’t limited to U.S. federal bills. It’s a common problem wherever cut and bite amending is employed, particularly in Commonwealth countrie or countries with Westminster based legislative traditions, even if the term cut and bite isn’t used.
At Xcential, we’re going to return to our core mission – to make government processes better through technology. Our goal is improved efficiency, increased accuracy, and most importantly, better transparency for the benefit of the citizens.
- The term cut and bite is also sometimes used to refer to the form of amending used to propose amendments to bills themselves. Another term for these types of bill amendments are page and line amendments as they usually are expressed as references to page and line numbers rather than to provisions. ↩︎






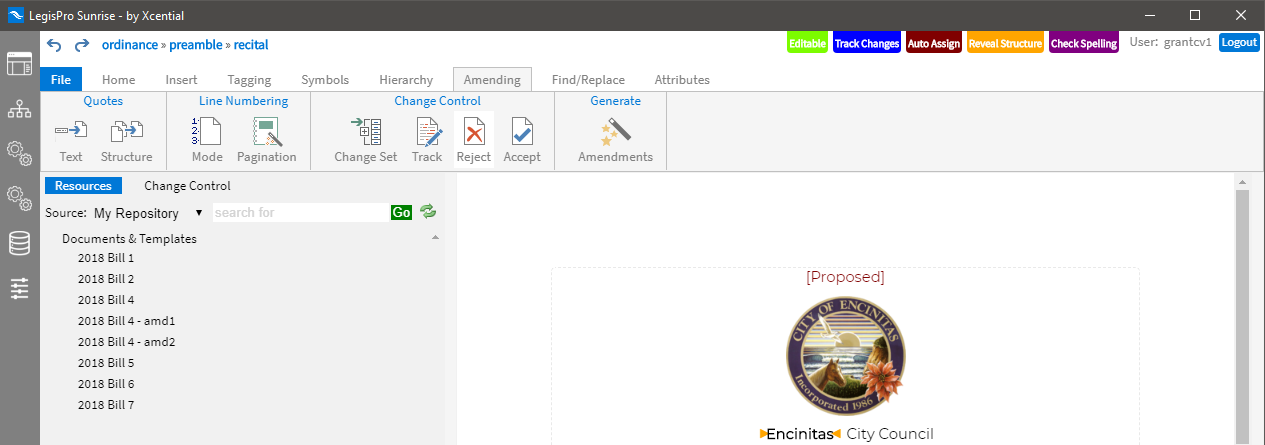
 In addition to the Sunrise edition, we offer LegisPro in customised FastTrack implementations of the LegisPro product or as fully bespoke Enterprise implementations where the individual components can be mixed and matched in many different ways.
In addition to the Sunrise edition, we offer LegisPro in customised FastTrack implementations of the LegisPro product or as fully bespoke Enterprise implementations where the individual components can be mixed and matched in many different ways.
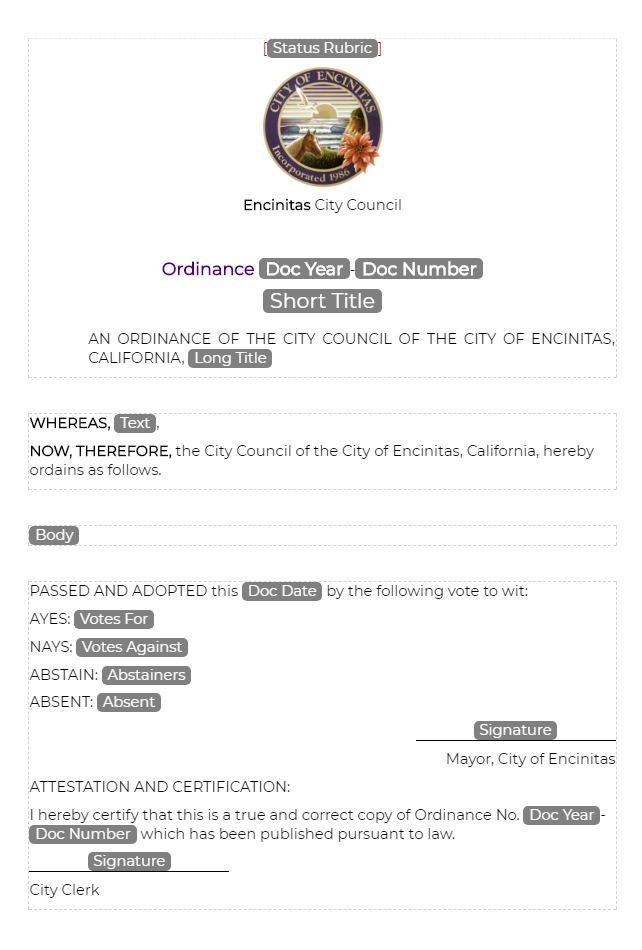 Templates allow the boilerplate structure of a document to be instantiated when creating a new document. Out-of-the-box, we are providing generic templates for bills, acts, amendments, amendment lists, and a few other document types.
Templates allow the boilerplate structure of a document to be instantiated when creating a new document. Out-of-the-box, we are providing generic templates for bills, acts, amendments, amendment lists, and a few other document types.




 A sidebar along the left side of the application provides access to the major components which make up LegisPro Sunrise. It is here that you can switch among documents, access on-board services such as the resolver and amendment generator, outboard services such as the document repository, and where the primary settings are managed.
A sidebar along the left side of the application provides access to the major components which make up LegisPro Sunrise. It is here that you can switch among documents, access on-board services such as the resolver and amendment generator, outboard services such as the document repository, and where the primary settings are managed.







 Later this week, Xcential will be announcing and showing the latest version of “Sunrise” version of LegisPro, at both
Later this week, Xcential will be announcing and showing the latest version of “Sunrise” version of LegisPro, at both 


 An authoring tool needs to hide or omit the unused parts of Akoma Ntoso, adapt the parts that are being used to fit the specific requirements of a jurisdiction, and allow for extension of Akoma Ntoso using the generic mechanism for extension in such a way that these extensions would appear to be seamless. As it turns out, almost a third of the elements we’ve implemented are extension elements. The result is an editor that allows a fully compliant Akoma Ntoso document to be drafted (correct by construction), while at the same time ensuring that the document fully complies with the jurisdiction’s model for how that document be represented.
An authoring tool needs to hide or omit the unused parts of Akoma Ntoso, adapt the parts that are being used to fit the specific requirements of a jurisdiction, and allow for extension of Akoma Ntoso using the generic mechanism for extension in such a way that these extensions would appear to be seamless. As it turns out, almost a third of the elements we’ve implemented are extension elements. The result is an editor that allows a fully compliant Akoma Ntoso document to be drafted (correct by construction), while at the same time ensuring that the document fully complies with the jurisdiction’s model for how that document be represented.






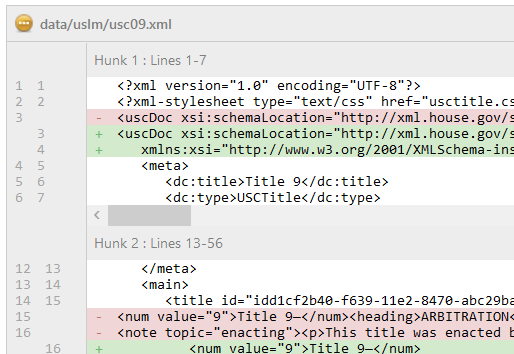





 Take a look at the totally contrived example on the left. It’s admittedly not a real example, it comes from my stress testing of the change tracking facilities. But look at what it does. The red text is a complex deletion that spans elements with little regard to the structure. In our editor, this was done with a single “delete” operation. Try and do this with XMetaL – it takes many operations and is a real struggle – even with change tracking turned off. In fact, even Microsoft Word’s handling of this is less than satisfactory, especially in more recent versions. Behind the scenes, the editor is using the model, derived from the schema, to control this deletion process to ensure that a valid document is the result.
Take a look at the totally contrived example on the left. It’s admittedly not a real example, it comes from my stress testing of the change tracking facilities. But look at what it does. The red text is a complex deletion that spans elements with little regard to the structure. In our editor, this was done with a single “delete” operation. Try and do this with XMetaL – it takes many operations and is a real struggle – even with change tracking turned off. In fact, even Microsoft Word’s handling of this is less than satisfactory, especially in more recent versions. Behind the scenes, the editor is using the model, derived from the schema, to control this deletion process to ensure that a valid document is the result.


 Input Form
Input Form Validation Results
Validation Results